how to not be an llm kiddie
Most people use llms the same way regardless of what they’re doing: hunting for an IDOR in a SaaS app, triaging a buffer overflow in a C codebase, or brainstorming names for a cat that will never answer to any of them. 😸
Then, they get slop back and either (a) report the vuln anyway, or (b) complain that “aI iS oVeRhYpEd”.
As you know, a script kiddie is someone who fires exploits they don’t understand against targets they can’t evaluate, claiming results they didn’t earn. But nowadays we also have the llm kiddies: those who throw every problem at a language model with zero understanding of when or how these things actually work.
Here I will share my mental model I use for using llms effectively so you don’t become one. Let’s go.
where llms are actually decent
OK, let’s be honest about some of the wins, because they’re real:
- pattern completion on well-understood domains: if there are 10K stackoverflow answers or 500 published CVEs with similar patterns, the llm will help you synthesize that knowledge fast. Known vulnerability classes, standard misconfigurations, documented attack techniques, etc.
- translation between representations: HTTP request to cURL command, burp log to python exploit script, raw bytes to structured analysis. Moving information across formats is bread and butter.
- first-draft generation: rough PoC scripts, report outlines, remediation recommendations. The key word is starting point.
- synthesis of known information: correlating CVEs, summarizing advisories, comparing documented attack paths. If the knowledge exists in the training data, it can compress it for you.
- rubber duck on steroids: explaining an attack chain back to you, stress-testing your methodology, helping you see logic gaps in your approach. IMHO, this one is underrated.
where llms suck
Now the part nobody selling you a “hack anything with AI 🌈” course wants you to hear:
- novel vulnerability discovery: if the bug doesn’t resemble a pattern in its training data, the model will fabricate one that sounds real: reports about vulnerabilities in functions that didn’t exist, buffer overflows in code that was bounds-checked, race conditions in single-threaded paths.
- understanding execution context: it doesn’t know what’s actually running on the server, how the WAF is configured, what sanitization the custom middleware does, or whether that
strcpyis actually reachable from user input. It knows tokens, not systems. - knowing what it doesn’t know: there’s no uncertainty flag. The model will produce a perfectly structured, CVSS-scored, impact-assessed wrong vulnerability report with the same confidence as a right one.
- causal reasoning about runtime behavior: it can pattern-match static code into known vulnerability templates. It cannot reason about heap layout, race windows, cache timing, or multi-step exploitation chains in systems it hasn’t memorized.
- taste and judgment: it will produce the statistical average of everything it’s seen, it has no direct practical experience.
the curl story: what llm kiddies actually destroy
If you want to see what happens when llm kiddies operate at scale, look at what happened to curl1.
In jul 2025, Daniel Stenberg2 published “Death by a thousand slops”, describing how AI-generated vulnerability reports were flooding the curl bug bounty on HackerOne. About 20% of all submissions were obvious AI slop, and only around 5% of total submissions turned out to be genuine vulnerabilities: a massive decline from the prior rate of over 15%.
The reports had titles like “Buffer Overflow Vulnerability in WebSocket Handling” and “HTTP Request Smuggling Vulnerability Analysis”: beautifully formatted, confidently stated, and completely fabricated, kek.
Each report engaged 3-4 security team members, sometimes for up to three hours each. Multiply that by the eight bogus reports they got in a single week and you’re looking at days of wasted expert time. All because someone asked ChatGPT to “hey, find vulnerabilities in curl” and submitted whatever it hallucinated.
Sadly, in jan 2026, the hammer dropped: “The end of the curl bug-bounty”. After 87 confirmed vulnerabilities and over $100K in bounties paid since 2019, the program was killed. No more monetary rewards. No more HackerOne. RIP. 🪦
Stenberg identified three converging bad trends:
- AI slop overwhelming the queue
- human reporters doing worse than ever (likely also misled by AI)
- submitters approaching with a bad-faith mindset: trying to twist anything into a critical vulnerability rather than genuinely helping improve the project
The program died because thousands of people who didn’t understand the problem domain used a tool they also didn’t understand, and buried the signal in noise. Apache Log4j’s bounty program reportedly headed the same direction3.
This is what the lack of a framework looks like. So let me give you one.
enter cynefin: matching the tool to the terrain
The Cynefin framework4 is a sense-making model to categorize situations according to their complexity and guide contextually appropriate decision-making processes.
This isn’t academic nor consulting fluff: it’s the most practical lens I’ve found for understanding when to trust an llm and when to trust your own brain, especially in security work. Stay with me, plz.
Here are the cynefin domains, oversimplified:
- 🔨 clear (obvious): cause and effect are obvious. best practice exists. sense → categorize → respond.
- 🧩 complicated: cause and effect require analysis or expertise. good practice exists. sense → analyze → respond.
- 🧪 complex: cause and effect are only coherent in retrospect. emergent practice. probe → sense → respond.
- 🌪️ chaotic: no cause and effect relationship perceivable. novel practice. act → sense → respond.
- 🧭 confusion (disorder): you don’t even know which of the previous domain you’re in.
Below is a visual representation of these domains:
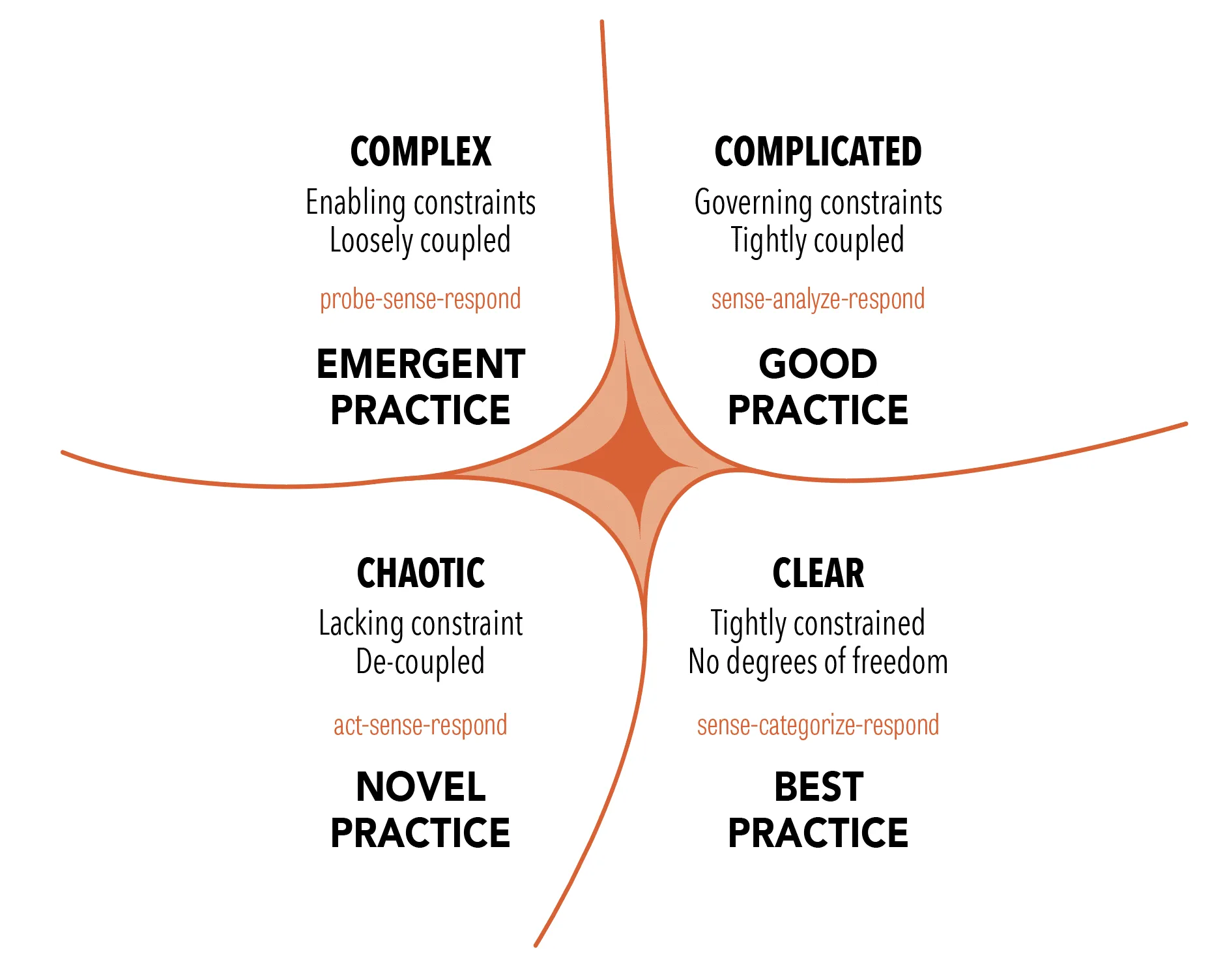
using llms in each cynefin domain
My take is that llms are nearly flawless in clear, they dominate in complicated, they degrade fast in complex, and they’re catastrophic in chaotic.
The idea is not to use the same prompt strategy everywhere, but to match it to the context of the specific problem.
Let’s break it down with practical examples:
🔨 clear: let the machine do the boring stuff
Clear problems have a known, unambiguous answer. In security work, this is the bread and butter: running a scan, checking a configuration against a benchmark, looking up a CVE, converting between formats. There’s one right answer, and it’s documented.
Key insight: in clear domains, the llm is a lookup and formatting engine. Don’t overthink it. Just be precise about what you need.
example #1: converting and checking known standards
I have an nmap scan result showing port 443 open on
192.168.1.50 with the following TLS ciphers accepted:
TLS_RSA_WITH_AES_128_CBC_SHA
TLS_RSA_WITH_3DES_EDE_CBC_SHA
TLS_ECDHE_RSA_WITH_AES_128_GCM_SHA256
TLS_ECDHE_RSA_WITH_AES_256_GCM_SHA384
TLS_RSA_WITH_RC4_128_SHA
Cross-reference each cipher against the current Mozilla
"Intermediate" TLS configuration guideline. For each one,
tell me: (a) pass or fail, (b) the specific reason if it
fails, (c) the exact nginx ssl_ciphers directive I need
to keep only the passing ciphers.
This is purely mechanical. The answer exists in Mozilla’s documentation. The llm is just doing lookup and formatting faster than you could. No judgment required.
example #2: translating between representations
Convert this raw HTTP request from Burp into a working
Python requests script. Preserve all headers exactly as-is,
handle the cookies, and add a variable at the top for the
session token so I can swap it easily:
POST /api/v1/transfer HTTP/1.1
Host: app.target.com
Cookie: session=eyJhbG...truncated
Content-Type: application/json
X-CSRF-Token: a1b2c3d4
{"from_account":"1001","to_account":"1002","amount":"500.00"}
Zero ambiguity. One correct output. Let the machine type it for you.
takeaways for the clear domain
- use the llm for: lookups, format conversions, boilerplate generation, standard compliance checks.
- don’t use the llm for: deciding whether the result matters. that’s your job.
- the failure mode: assuming something is clear when it’s actually complicated. Try to verify the output against the actual source of truth (the RFC, the docs, the spec).
🧩 complicated: where llms earn their keep
This is the sweet spot. The vulnerability class is well-documented. Exploitation techniques are published. The OWASP has been written about ten thousand times. The answer exists, but it requires expertise to connect the dots for your specific target.
Key insight: in complicated domains, you want the llm to act as a senior practitioner. Be specific about your target context, the tech stack, what you’ve already tried, and what your constraints are.
example #1: analyzing a specific authentication flow
I'm testing a B2B SaaS application. The auth flow works like this:
1. POST /api/v2/auth/login with {email, password} returns a JWT
in the response body (not httpOnly cookie)
2. JWT contains claims: sub, org_id, role (values: "member",
"admin", "owner"), exp, iat
3. JWT is signed with RS256. I've confirmed the public key is
served at /.well-known/jwks.json
4. The org_id claim is used server-side to scope data access:
changing org_id in requests to /api/v2/resources/* returns
403 for cross-org access
5. BUT: I noticed the PUT /api/v2/users/{id}/role endpoint only
checks that the JWT is valid: it does NOT appear to verify
the caller's role claim against the target user's org
Given this specific flow:
(a) What is the most likely privilege escalation path?
(b) Draft me a precise Burp Suite repeater test: original
request vs. modified request, what I should see if the
authz check is missing
(c) What other endpoints should I test for the same pattern
of "authn without authz"?
Here you gave the model real observations from real testing. You described the specific behavior you’ve already confirmed. Now it can draw on deep patterns from thousands of similar authorization bypass findings to help you complete your analysis. You’re the pilot. It’s the instruments panel.
example #2: crafting a targeted SSRF payload
Target is running a Node.js application behind Cloudflare. I've
found an endpoint POST /api/integrations/webhook that accepts a
{"callback_url": "..."} parameter.
What I've tested so far:
- Direct http://169.254.169.254: blocked, returns
"invalid URL" error
- http://0x7f000001: blocked
- DNS rebinding with my server: inconsistent, sometimes works
- http://[::ffff:169.254.169.254]: returns different error:
"connection refused" (suggesting it passed URL validation
but couldn't connect)
The IPv6 variant returning "connection refused" instead of
"invalid URL" suggests the URL parser accepts it but the
network layer blocks it.
Given this behavior differential, what specific bypass
techniques should I try next? Focus on URL parser confusion
between the validation layer and the actual HTTP client (likely
node-fetch or axios). Give me the 5 highest-probability
payloads in order.
This is a complicated problem. The vulnerability class (SSRF) is well-known. The bypass techniques are documented. But connecting the specific parser behavior to the right bypass requires expertise that the llm has in abundance: because it’s seen thousands of SSRF writeups. You’re giving it the data from your actual testing and asking it to narrow the search space.
takeaways for the complicated domain
- use the llm for: expert-level analysis of well-known vulnerability classes, payload generation against specific tech stacks, tradeoff analysis between exploitation approaches, mapping your observations to documented attack patterns.
- don’t use the llm for: confirming the vulnerability exists. you test it. you run the payload. you check the response.
- the failure mode: submitting the llm’s analysis as your finding without verifying it. this is the step the slop reporters skipped.
🧪 complex: where you lead and the llm follows
Complex domains are where emergence lives. The target’s architecture is novel. The vulnerability chain requires combining multiple low-severity issues in ways nobody has documented. The attack surface shifts as you probe it. The relationship between cause and effect only makes sense looking backward.
Key insight: in complex domains, the llm is not your exploit generator. It’s your sparring partner. You use it to stress-test your methodology, generate diverse hypotheses, and map the possibility space. You do the probing. You observe the behavior. The llm helps you think, not pwn.
My take is that most slop reporters that overwhelmed bb programs failed here specifically. They treated a complex problem (finding real vulnerabilities in a mature, heavily-audited C codebase) as if it were complicated (just apply known patterns). The llm told them what they wanted to hear, kek.
example #1: mapping an unconventional attack surface
I'm testing a target with a GraphQL API. Here's what I've
mapped so far through introspection and traffic analysis:
- Introspection is disabled in production, but I recovered
a partial schema from a JS source map at /static/js/app.
chunk.js (extracting Apollo client cache references)
- There are ~40 queries and ~15 mutations I've identified
- The API uses cursor-based pagination with opaque base64
cursors: I decoded one and it's a JSON with {table, id,
created_at}. Changing the "table" field returns data from
different tables
- Rate limiting appears to be per-query-name, not per-request.
Aliased queries bypass the rate limit entirely
- There's a `searchUsers` query that accepts a `filter` param
that looks like it maps directly to a database WHERE clause
I'm NOT asking you to tell me what's vulnerable. I want you
to challenge my attack methodology:
1. What am I likely overlooking in this enumeration?
2. Given the cursor structure leaking table names, what's
the highest-value probe I should run next?
3. The filter→WHERE mapping smells like injection: but
what are the 3 most common ways GraphQL layers sanitize
this that I should rule out before spending hours on it?
4. What would a contrarian pentester do differently here?
Note you’re using the llm to sharpen your own approach. You maintain agency. The model provides cognitive diversity you’d otherwise need a teammate for.
example #2: chaining low-severity bugs
I've found three separate low-severity issues on the same target:
1. Reflected XSS in an error message on /legacy/search?q=
(CSP blocks inline scripts, but allows 'unsafe-eval'
and scripts from *.googleapis.com)
2. An open redirect at /auth/callback?next= (validated to
same origin but fails on /auth/callback?next=//evil.com)
3. A CSRF in the email-change flow at /settings/email
(SameSite=Lax on session cookie, no CSRF token, but
requires re-entering current password)
Individually these are all P4/informational at best. I suspect
there's a chain here but I haven't found it yet.
Don't give me the answer. Instead:
(a) What trust boundaries do these three issues share?
(b) What's the one piece of information I'm missing that
would tell me whether a chain exists?
(c) Sketch me 2 possible chain hypotheses I should test:
not full exploits, just the logical path I need to
validate or invalidate.
This is complex territory. The chain is emergent: it only becomes visible through probing and creative combination. The llm is good at generating hypotheses because it’s seen lots of chain writeups. But ideally you should to check each link yourself.
takeaways for the complex domain
- use the llm for: hypothesis generation, methodology critique, mapping possibility spaces, identifying what you might be overlooking, synthesizing analogies from other targets or domains.
- don’t use the llm for: deciding what’s true. only probing the real system tells you that.
- the failure mode: treating the llm’s hypothesis as a finding. it’s a direction to test, not a result.
🌪️ chaotic: where you act first and think later
Chaos means there is no perceivable relationship between cause and effect. In security, this is an active incident, an unexpected zero-day disclosure, a red team engagement where the defenders just detected you and your infrastructure is burning down.
the key insight: in chaotic domains, the llm’s main value is speed of ideation. You need options fast. You don’t need them to be perfect: you need them to be actionable right now.
example #1: IR containment brainstorming
We just discovered active exploitation of our customer-facing
Rails app. Access logs show requests to /admin/impersonate
from 3 different source IPs starting 4 hours ago. The endpoint
should require admin auth but the logs show 200 responses with
non-admin session cookies. We think there's an auth bypass but
we haven't identified the root cause yet.
Don't give me a root cause analysis. Give me an immediate
triage plan: the first 5 actions in order, each executable
in under 10 minutes, to contain the damage while we
investigate:
Constraints:
- App runs on Kubernetes behind nginx ingress
- We have ~200 concurrent users we can't fully take offline
- We do have the ability to deploy nginx config changes
in <2 minutes via Helm
This isn’t analysis. This is “give me a reasonable first containment move while my brain is flooded with cortisol”. The llm is good at this because it can recall incident response patterns while you’re too panicked to think straight.
Don’t treat it as the source of truth; always validate it against your own take. I usually ask after drafting an initial approach. If we both land on the same idea, that’s a strong signal. It’s basically ensemble learning.
example #2: red team: oops, you just got caught
I'm on a red team engagement. The blue team just killed my
C2 callback from the compromised workstation. I still have
an active SSH tunnel through a pivot host to an internal
Jenkins server (credentials cached). The tunnel could die
any minute.
I need 3 options for re-establishing persistence RIGHT NOW,
ranked by stealth. Assume:
- I have root on the Jenkins box (Linux, Ubuntu 22.04)
- Jenkins has outbound HTTPS allowed through the proxy
- I do NOT have credentials for any other internal systems
- Blue team is actively hunting: anything noisy is burned
immediately
Speed over perfection. What do I do in the next 5 minutes?
Speed. Options. Known operational tradecraft. You pick, you act, you sense the response. That’s chaotic domain management. The llm generates the menu; you make the call.
But again: do not assume that menu is complete or correct right away. Be skeptic by default. We are navigating unexplored territory here.
takeaways for the chaotic domain
- use the llm for: rapid option generation, triage checklists, brainstorming ideas when you can’t think straight.
- don’t use the llm for: strategy. In chaos you don’t have time for strategy. You stabilize first, then move the problem into a domain where analysis is possible.
- the failure mode: treating the llm’s first suggestion as gospel. It gave you a menu, not an order. Read the room, pick fast, and adapt.
do your homework
Here’s what the llm kiddies doesn’t get: knowing the limitations of llms is itself a competitive advantage.
My take is that the tool isn’t the problem, but the lack of a mental model for when and how to use it.
Ultimately, every idiot can prompt. Not everyone can think. The llm doesn’t replace the second part. It amplifies whichever one you bring to it. 🧠
-
curl is used in virtually every internet-connected device and operating system. It’s one of the most critical and widely-deployed pieces of open source infrastructure in existence. ↩
-
the creator and maintainer of curl ↩
-
Piotr P. Karwasz, Apache Log4j PMC member, confirmed in the comments on Stenberg’s post that Log4j’s bounty program faced the same dynamic and was heading toward closure by end of feb 2026. ↩
-
the Cynefin framework was created by Dave Snowden in 1999 while working at IBM Global Services. The name is Welsh, meaning “habitat” or “place of belonging.” The framework is widely used in organizational strategy, knowledge management, and decision-making under uncertainty. See Snowden, D.J. and Boone, M.E. (2007), “A Leader’s Framework for Decision Making,” Harvard Business Review. ↩
Hey, I'd love to hear your thoughts! Just drop me an email.